Hashing
(Diagram was created by me)
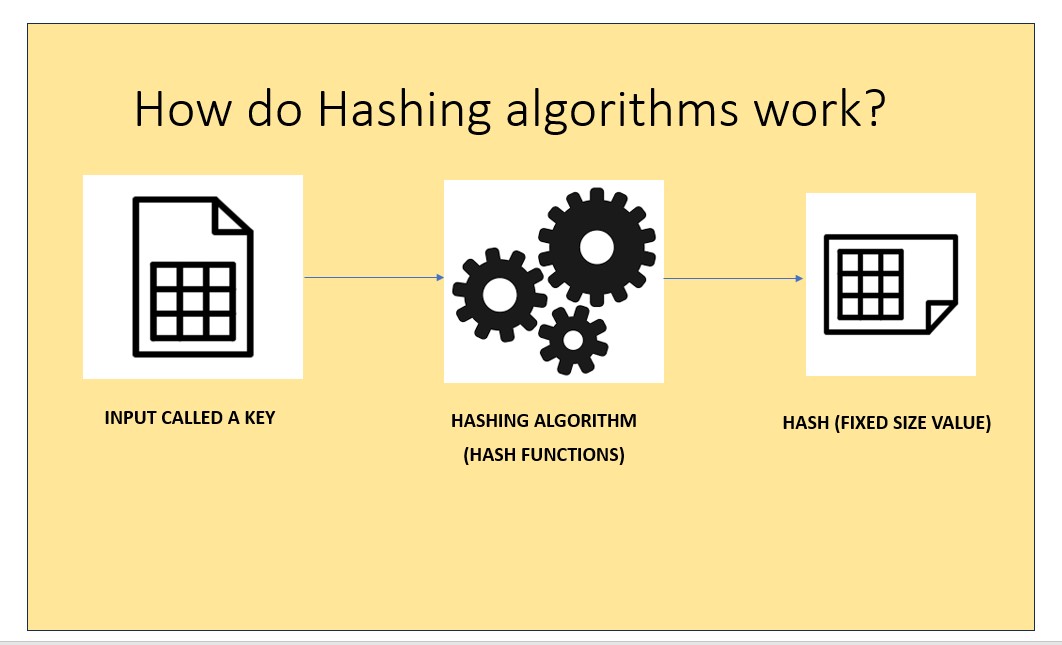
Hashing is the name given to a process in which an input (called a key) is turned into a fixed size value (called a hash). There are a vast number of algorithms, called hash functions, which do this.
Unlike encryption, the output of a hash function can’t be reversed to form the key. This quality makes hashing useful for storing passwords. A password entered by a user can be hashed and checked against the key to see if it is correct, but a successful hacker would only gain access to the keys, which can’t be reversed to gain the passwords.
Hash Tables
Another use of hashing is hash tables. A hash table is a data structure which holds key-value pairs. Formed from a bucket array and a hash function, hash tables can be used to lookup data in an array in constant time. When data needs to be inserted, it is used as the key for the hash function and stored in the bucket corresponding to the hash.
Hash tables are used extensively in situations where a lot of data needs to be stored with constant access times. For example, in caches and databases. If two pieces of data (keys) produce the same hash, a collision is said to have occurred.
For example, in the image above the keys John and Sandra both hash to 02. There are a variety of methods to overcome collisions, including storing items together in a list under the hash value, or using a second hash function to generate a new hash.
A Good Hash Function
A good hash function should have a low chance of collision and should be quick to calculate. Furthermore, a hash function should provide an output which is smaller than the input it was provided, otherwise searching for the hash could take longer than simply searching for the key.
Principles of Hashing Algorithms
Many different hashing algorithms exist, and they all work a little differently. But in each one, people type in data, and the program alters it to a different form.
All hashing algorithms are:
Mathematical. Strict rules underlie the work an algorithm does, and those rules can’t be broken or adjusted.
Uniform. Choose one type of hashing algorithm, and data of any character count put through the system will emerge at a length predetermined by the program.
Consistent. The algorithm does just one thing (compress data) and nothing else.
One way. Once transformed by the algorithm, it’s nearly impossible to revert the data to its original state.